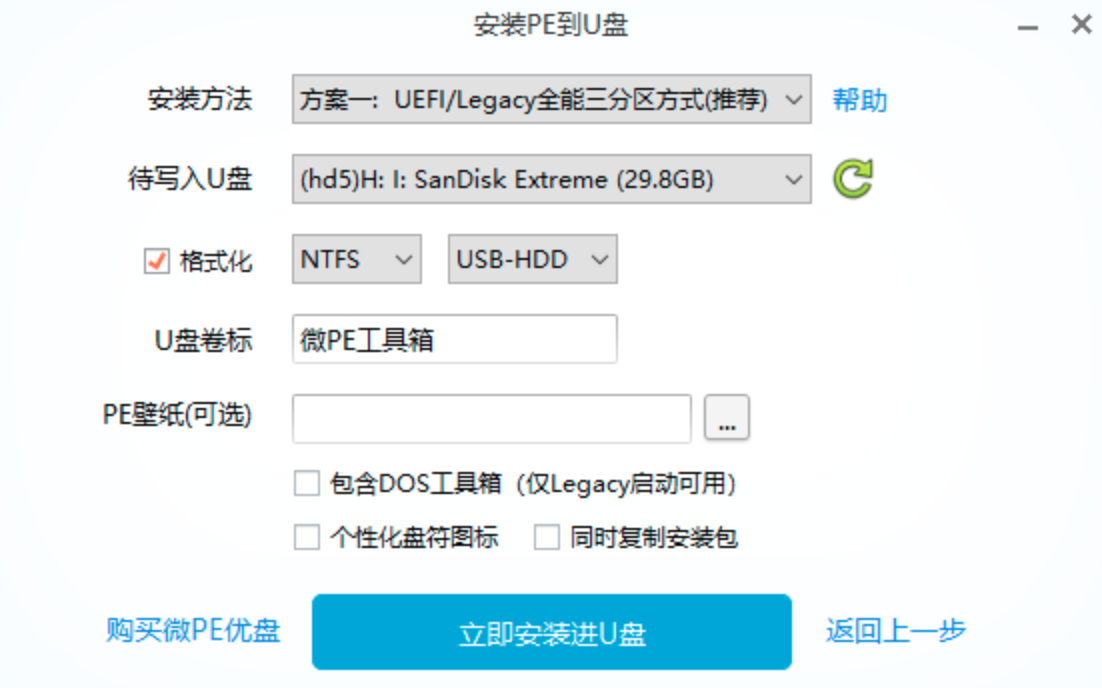
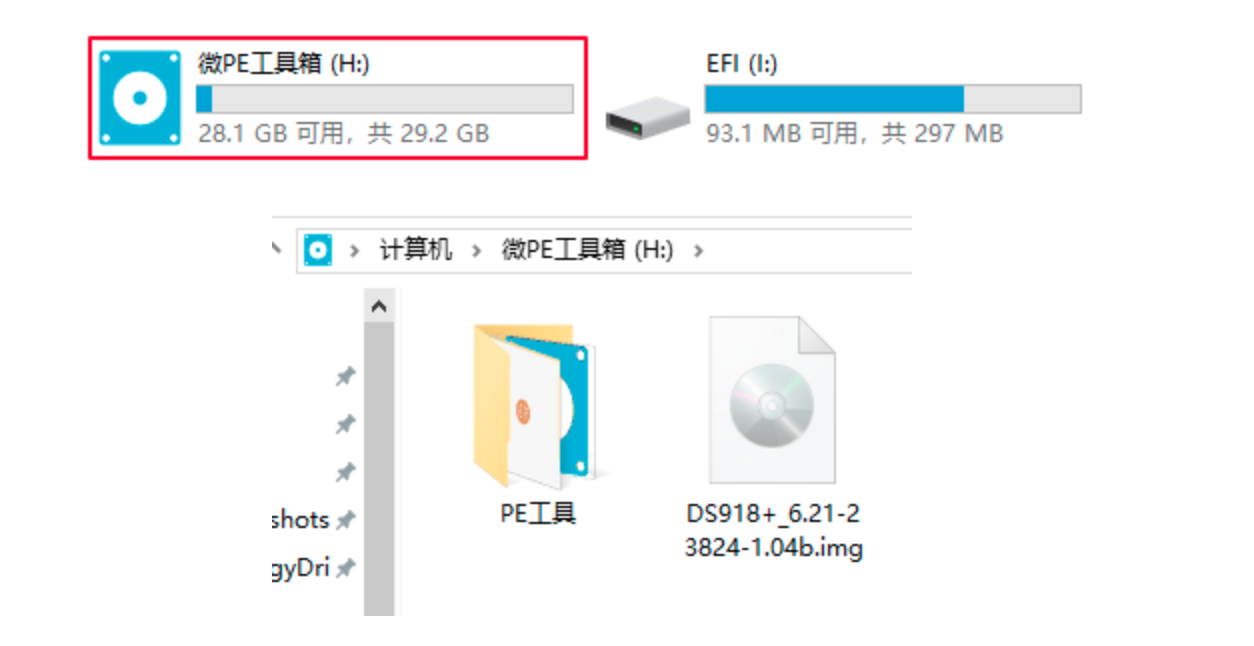
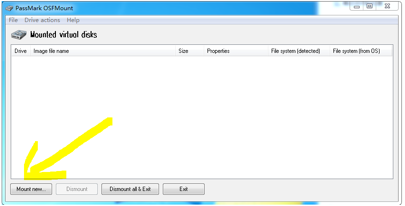
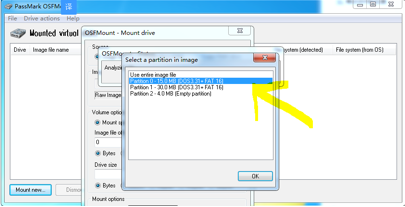
首先有几点需要说明的是:Programming iOS 9是一本很不错的书,纸质书很厚,看完真的是需要毅力的。
这个笔记谈不上翻译,当然目前很大一部分是借鉴http://wdxtub.com/ 这个blog里的笔记【这个blog文章我常看】,我只是在上面作了一些修改。
为什么这么说呢?因为我操作的环境是在swift3+Xcode8+iOS10。
我只是业余的、业余的、业余的学习iOS开发,如果里面什么错误,欢迎指正!欢迎iOS大牛带我飞。
首先补充一些知识点(关于CGRect、“NS”和UserDefaults的变化):
CGRect:
CGPoint
CGSize
UIColor
“NS”
UserDefaults
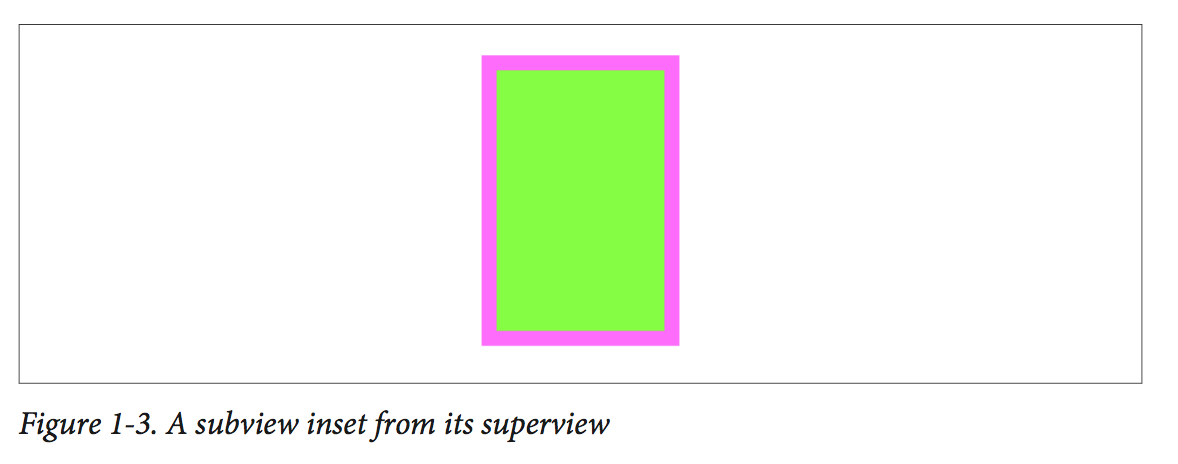
Bounds and Center 假设有一个Superview和一个subview,subview是被嵌入了10个points。如图所示:1
2
3
4
5
6
7
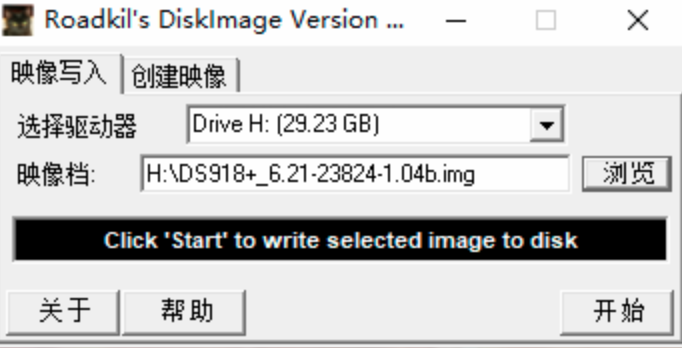
let v1 = UIView (frame: CGRect (x: 113 , y: 111 , width: 132 , height: 194 ))
v1.backgroundColor = UIColor (red: 1 , green: 0.4 , blue: 1 , alpha: 1 )
let v2 = UIView (frame: v1.bounds.insetBy(dx: 10 , dy: 10 ))
v2.backgroundColor = UIColor (red: 0.5 , green: 1 , blue: 0 , alpha: 1 )
mainview?.addSubview(v1)
v1.addSubview(v2)
关于bounds的属性是一个view在自己的坐标系中的矩形尺寸(frame是在superview的坐标系的)。
我们通常都是如此使用bounds的用法。当你需要往一个view里面放东西的时候,无论是手动绘制们还是放一个subview,通常都要使用view的bounds。
当你改变一个view的bounds,他的frame也会对应改变,frame的改变是基于其中心点的(中心点不会变)。
在上面的代码增加两行:1
2
3
4
5
6
7
8
9
let v1 = UIView (frame: CGRect (x: 113 , y: 111 , width: 132 , height: 194 ))
v1.backgroundColor = UIColor (red: 1 , green: 0.4 , blue: 1 , alpha: 1 )
let v2 = UIView (frame: v1.bounds.insetBy(dx: 10 , dy: 10 ))
v2.backgroundColor = UIColor (red: 0.5 , green: 1 , blue: 0 , alpha: 1 )
mainview?.addSubview(v1)
v1.addSubview(v2)
v2.bounds.size.height += 20
v2.bounds.size.width += 20
效果图如下:就是v2基于中心点不变,height和width属性值都增加了20个points,结果就是完全覆盖了紫色的view。
还可以变着花样来:
再增加两行代码:1
2
v1.bounds.origin.x += 10
v1.bounds.origin.y += 10
效果图如下:
不难看出view向原点移动方向的反方向进行了移动,这个因为一个view 的原点是与其frame的左上角一致。
其实我们可以发现:改变view的bounds size是会影响frame的Size,反之亦然,唯一不变的是view的center,。这个属性,跟frame的属性一样,这表示一个subview的位置是在其Superview的坐标系中的位置。通过下面的代码是可以获取的:1
let c = CGPoint (theView.bounds.midX, theView.bounds.midY)
改变 view 的 bounds 不会影响其 center,改变一个 view 的 center 不会影响其 bounds。所以其实一个 view 的 bounds 和 center 就可以确定其在 superview 中的位置,frame 可以看作是一个由 bounds 和 center 组成的表达式的简便写法而已。注意有些情况下 frame 会没有什么意义,但是 bounds 和 center 总是有效的,所以建议多用 bounds 和 center 的组合,也比较容易理解。
bounds: 一个 view 自己的坐标系统
center: 一个 view 的坐标系统和其 superview 的坐标系统的关系
以下方法是可以进行不同view之间的坐标转换:
convert(point: CGPoint, from: UIView?), convert(point: CGPoint, to: UIView?)
convert(rect: CGRect, from: UIView?), convert(rect: CGRect, to: UIView?)
如果第二参数为nil,那么就取window的值。比如:如果v2是v1的subview,那么要把v2放到v1的中心,就用:1
v2.center = v1.convert(v1.center, from: v1.superview)
注意,通过改变 center 来设置 view 的位置时,如果高或宽不是偶数,那么可能会导致 misaligned。可以通过打开模拟器的 Debug -> Color Misaligned Images 来进行检测。一个简单的方法是调整好位置之后调用 makeIntegralInPlace 来设置 view 的 frame。
Window Coordinates 和 Screen Coordinates 设备屏幕是没有 frame 的,但是有 bounds。Main window 也没有 superview,不过其 frame 被设置为屏幕的 bounds,如:
1
let w = UIWindow (frame: UIScreen .main.bounds)
在绝大数的情况下,window 坐标系就是 screen 坐标系。现在的iOS中坐标系和手机是否选择是有关的,有如下两个属性:
可以用下面的方法来对不同坐标空间进行转换:
convert(point: CGPoint, from: UICoordinateSpace), convert(point: CGPoint, to: UICoordinateSpace),
convert(rect: CGRect, from: UICoordinateSpace), convert(rect: CGRect, to: UICoordinateSpace)
假设界面中有一个 UIView v,我们想知道它的实际设备坐标,可以用下面的代码:
1
let r = v.superview!.convert(v.frame, to: UIScreen .main.fixedCoordinateSpace)
一个 view 的 transform 属性改变这个 view 是如何被绘制的,实际上就是一个 CGAffineTransform类的 3x3 矩阵。所有的变换都是以这个view的center做基准的,下面的具体实例:1
2
3
4
5
6
7
let v1 = UIView (frame: CGRect (x: 113 , y: 111 , width: 132 , height: 194 ))
v1.backgroundColor = UIColor (red: 1 , green: 0.4 , blue: 1 , alpha: 1 )
let v2 = UIView (frame: v1.bounds.insetBy(dx: 10 , dy: 10 ))
v2.backgroundColor = UIColor (red: 0.5 , green: 1 , blue: 0 , alpha: 1 )
mainview?.addSubview(v1)
v1.addSubview(v2)
v1.transform = CGAffineTransform (rotationAngle: 45 * CGFloat (M_PI )/180.0 )
效果图入下:旋转了45度
注意,这里的view的center和bounds都没有变,但是frame的数值已经没有意义,因为现在它的尺寸是能够覆盖当前view的最小矩形,并不会随着view的旋转而旋转。
1
2
3
4
5
6
7
let v1 = UIView (frame: CGRect (x: 113 , y: 111 , width: 132 , height: 194 ))
v1.backgroundColor = UIColor (red: 1 , green: 0.4 , blue: 1 , alpha: 1 )
let v2 = UIView (frame: v1.bounds.insetBy(dx: 10 , dy: 10 ))
v2.backgroundColor = UIColor (red: 0.5 , green: 1 , blue: 0 , alpha: 1 )
mainview?.addSubview(v1)
v1.addSubview(v2)
v1.transform = CGAffineTransform (scaleX: 1.8 , y: 1 )
效果如下:
view的bounds仍然不收影响,因为subview仍然绘制在相对于Superview的位置。也就是说这个两个view在水平方向一起拉伸。
代码:1
2
3
4
5
6
7
8
let v1 = UIView (frame: CGRect (x: 20 , y: 111 , width: 132 , height: 194 ))
v1.backgroundColor = UIColor (red: 1 , green: 0.4 , blue: 1 , alpha: 1 )
let v2 = UIView (frame: v1.bounds)
v2.backgroundColor = UIColor (red: 0.5 , green: 1 , blue: 0 , alpha: 1 )
mainview?.addSubview(v1)
v1.addSubview(v2)
v2.transform = CGAffineTransform (translationX: 100 , y: 0 )
v2.transform = v2.transform.rotated(by: 45 * CGFloat (M_PI )/180.0 )
效果图如下:
再变,代码只需要改动如下:1
2
v2.transform = CGAffineTransform (rotationAngle: 45 * CGFloat (M_PI )/180.0 )
v2.transform = v2.transform.translatedBy(x: 100 , y: 0 )
效果图如下:
还有一种方法能实现上图的效果:1
2
3
let r = CGAffineTransform (rotationAngle: 45 * CGFloat (M_PI )/180.0 )
let t = CGAffineTransform (translationX: 100 , y: 0 )
v2.transform = t.concatenating(r)
继续增加下面的代码:1
v2.transform = r.inverted().concatenating(v2.transform)
效果图如下:
再来一个变换:1
2
3
4
5
6
7
let v1 = UIView (frame: CGRect (x: 113 , y: 111 , width: 132 , height: 194 ))
v1.backgroundColor = UIColor (red: 1 , green: 0.4 , blue: 1 , alpha: 1 )
let v2 = UIView (frame: v1.bounds.insetBy(dx: 10 , dy: 10 ))
v2.backgroundColor = UIColor (red: 0.5 , green: 1 , blue: 0 , alpha: 1 )
mainview?.addSubview(v1)
v1.addSubview(v2)
v1.transform = CGAffineTransform (a: 1 , b: 0 , c : -0.2 , d: 1 , tx: 0 , ty: 0 )
效果图如下:
Trait Collections and Size Classes 界面上的每个 view 都有一个 traitCollection 属性,值是一个 UITraitCollection,包含下面四个属性:
displayScale,由当前屏幕决定的缩放尺寸,1(single resolution) 2(double resolution) 3(iPhone 6/6s/7 Plus)
userInterfaceIdiom,一个 UserIterfaceIdiom 值,可能是 .Phone 或 .Pad,来标志不同的设备,默认来说和 UIDevice 的 userInterfaceIdiom 属性一致.
horizontalSizeClass, verticalSizeClass,是 UIUserInterfaceSizeClass 值,可能是 .Regular 或 .Compact
水平和竖直都是 .Regular -> iPad
水平是 .Compact 竖直是 .Regular -> iPhone 在垂直方向,或者 iPad 的分屏应用
水平和竖直都是 .Compact -> iPhone 在水平方向(iPhone 6/6s/7 plus除外)
水平是 .Regular 竖直是 .Compact -> iPhone 6/6s/7 Plus 在水平方向
当应用运行时如果 trait collection 发生改变,会调用 traitCollectionDidChange 方法。
Layout 假设superview的bounds变化,其subview的bounds和center是不会变的,实际应用中,我们可能更需要subview根据Superview的变化而变化,这就是Layout。
Layout的主要执行方式:
Manual layout(手动layout)
Autoresizing
Authlayout
通常不会用到手动 layout,autoresizing 基本也是自动的,autolayout 主要在 xCode 的编辑器中进行设定。在代码中创建的 view 默认使用 autoresizing 而不是 autolayout。
]]>